
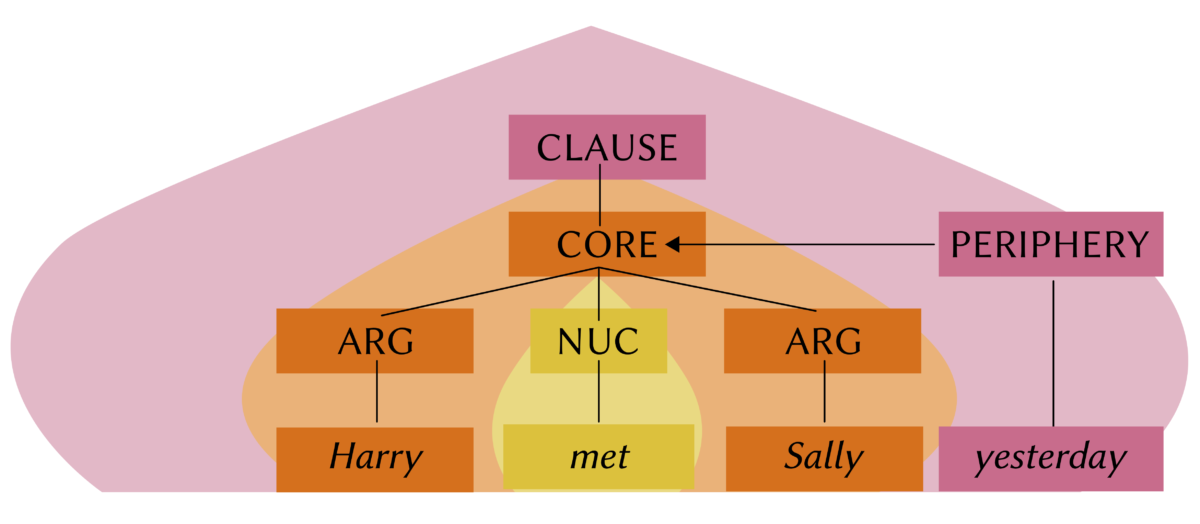
In the MA program, I taught a class on syntactic recursion during the winter term 2020/21. This is a topic that I have studied quite extensively before, and it features prominently in several past and ongoing grant proposals. I also think it’s an important and interesting topic that touches several fundamental debates in linguistics. I’m quite happy with the selection of texts we ended up discussing and the overall format. You can find my syllabus here.
News
Daakaka grammar class
One of the wonderful features of the linguistics curriculum at HHU are the obligatory classes on structures of non-Indoeuropean languages. They take 4 hours per week, instead of the regular 2, and I’m looking forward to teaching them on a regular basis. For the winter term of 2020/21, I taught a class on Daakaka. I’m quite happy with how it turned out, and so were my students. In the future, I’ll have to put more work into creating coherence. I might have gone a little wild with all the great tools one can explore during practice sessions. The syllabus can be found here. Since this was an online class, I also created short video lectures, some of which can be found here. If you want access to the full class on Moodle, or have comments or questions, don’t hesitate to contact me.
Exploring linguistic typology through language puzzles
In this class, we solve a linguistic puzzle each week, primarily from the International Olympiad of Linguistics. Topics include writing systems, number systems, verbal morphology, kinship systems, and others. I first taught this class in the winter of 2020/21. You can use my syllabus for inspiration, if you’d like to try this out. My students loved the class and so did I. Since this was a distant-learning class, I also prepared short video lectures for each session. You can watch some of them at the HHU mediathek. I will definitely teach this class again, probably with varying sets of puzzles.
Lyrics for Chinese class
Update: I did get great feedback on the lyrics by Charles Yang, who commented on exactly those places I was uneasy about. I updated the translation and am now finally getting around to uploading my homepage. You’ll find the revised translation under the link below. For more glossed texts, also see this post.
I’ll be posting a lot more about teaching here, since that is the current focus of my work. A most wonderful feature of the Düsseldorf curriculum are the classes on grammars of non-Indo-European languages, which take two sessions per week, rather than the usual one. This semester, I’ve been teaching Daakaka, and it’s been an intensely gratifying experience, on which I’ll certainly post more later. Right now, I’m planning a class on Mandarin Chinese for the summer term, and I decided to dedicate part of it to the worship of a song that I absolutely adore. It’s by the band 二手玫瑰 (èrshǒu méigui, Second Hand Rose), and I would translate it as “Let the artists get rich and their wealth trickle down”. The title is based on a quote by Deng Xiaoping, who said, basically, not everyone had to get rich at the same time, it was ok if a few people got rich first and passed on some of their wealth to their neighbours. I have glossed and translated the lyrics, take a look if you’re interested, and please let me know if you have more information about the song!
AFLA 2020
I’m very excited about this year’s AFLA 2020. The organizers are doing a fantastic job at hosting it online. You can see the program and download all the slides here. There is also a youtube channel where all the talks have been posted. I haven’t been able to see all talks live so far, due to different time zones, but I have been very impressed with the quality of those talks that I have seen. It’s definitely worth taking a look. I used my slot to work on my greater narrative about how Oceanic languages can change our understanding about the relation between tense and modality, and between time and reality.
The German Olympic Linguists
I should have gotten around to this earlier, but here goes: Together with my colleagues at ZAS, Nathalie Topaj and André Meinunger, I organized the selection of the German team for the International Olympiad of Linguistics again this year, even though there it won’t take place this year.There is a short report on the ZAS homepage.
We have always been dealing with scarce resources, but this year, of course, also had to figure in the pandemic. We held all three rounds of competitions online. I missed talking to the students in present. Even so, I think we all had great fun with the puzzles. I had lots of help from colleagues in designing the puzzles, in particular Qiang Xia, Johanna Kimmerl, Christian Döhler and Sebastian Nordhoff, so we ended up with a fantastic range of languages and phenomena. I’m planning to make all puzzles accessible to the public eventually.
Multiverb constructions at the syntax-semantics interface
The last talk of 2019 was an invited talk in Düsseldorf, where I presented some of my recent work on adverbial serial verb constructions in Daakaka and beyond. You can download my slides here.
Out now: Expressing possibility in two Oceanic languages
We can often choose between more basic, highly grammaticalized, ways to express a given meaning, and more verbose ways of doing so. Thus, in English, we may say “Brenda can catch the train” or “it is possible that Brenda will catch the train”, with quite similar interpretations. In my article with Anna Margetts, we argue that expressions of possibility in Daakaka and Saliba-Logea correspond to it is possible that in terms of their syntactic complexity, but to can in terms of their paradigmatic properties, frequencies and meaning. Look at the publication here or download the preprint.
Paradigms and rules
I was invited to the University of Potsdam to talk about some of my recent work on morphology. I took the opportunity to discuss some of my observations about word-like properties of complex phrases, in particular the way they combine into word-like paradigms. You can see my slides here.
How many books fit into a suitcase?

Turns out, not that many. I’m moving offices from HU to ZAS right now, and it will take a few more trips through Berlin Mitte before the handsome shelves of my new office are filled. I’ll post more about my new position and rewrite my landing page as soon as I’ve figured out who I am right now, so watch this space.