
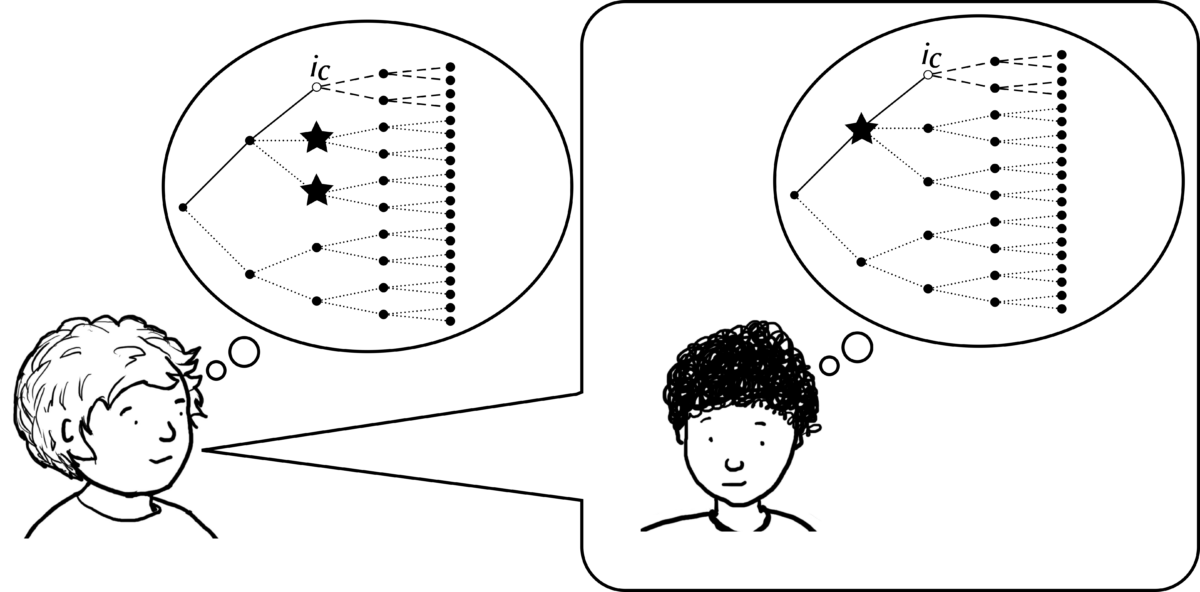
I was very happy to join a recent workshop on mistaken beliefs, organized by Simon Wimmer. I learned about intriguing new research by colleagues, and took the opportunity to present some ideas that relate contrafactivity to counterfactuality as expressed in natural languages. You can find my slides here.
Category: Talks
APLL 2024
Wrapping up 2022: more talks and publications
I haven’t been posting regularly about recent talks and publications, so here are a few more highlights from the second part of 2022:
- Colleagues and I published a paper on training RRG parsers on low resource languages, including Daakaka data.
- I gave a talk at the awesome linguistics department in Cologne, with a few more thoughts about wordhood in Daakaka.
- I was also invited to the phenomenal UT Texas (which curiously expands to University of Texas at Austin) department of linguistics, which combines two of my favourite subjects, linguistic fieldwork and formal semantics. This gave me a chance to get back to some of my ideas about modal semantics.
Freiburg 2022
The semester ended for me with a highly enjoyable visit at Uta Reinöhl’s lab in sunny Freiburg. I took the opportunity to talk about a puzzle concerning the role and emergence of word units in Oceanic. I’m currently writing a research proposal in the context of a Collaborative Research Centre we’re cooking up at HHU, where I hope to shed more light on this fascinating conundrum.
AFLA 2020
I’m very excited about this year’s AFLA 2020. The organizers are doing a fantastic job at hosting it online. You can see the program and download all the slides here. There is also a youtube channel where all the talks have been posted. I haven’t been able to see all talks live so far, due to different time zones, but I have been very impressed with the quality of those talks that I have seen. It’s definitely worth taking a look. I used my slot to work on my greater narrative about how Oceanic languages can change our understanding about the relation between tense and modality, and between time and reality.
Multiverb constructions at the syntax-semantics interface
The last talk of 2019 was an invited talk in Düsseldorf, where I presented some of my recent work on adverbial serial verb constructions in Daakaka and beyond. You can download my slides here.
Paradigms and rules
I was invited to the University of Potsdam to talk about some of my recent work on morphology. I took the opportunity to discuss some of my observations about word-like properties of complex phrases, in particular the way they combine into word-like paradigms. You can see my slides here.
Reciprocal strategies in a language without reciprocal markers

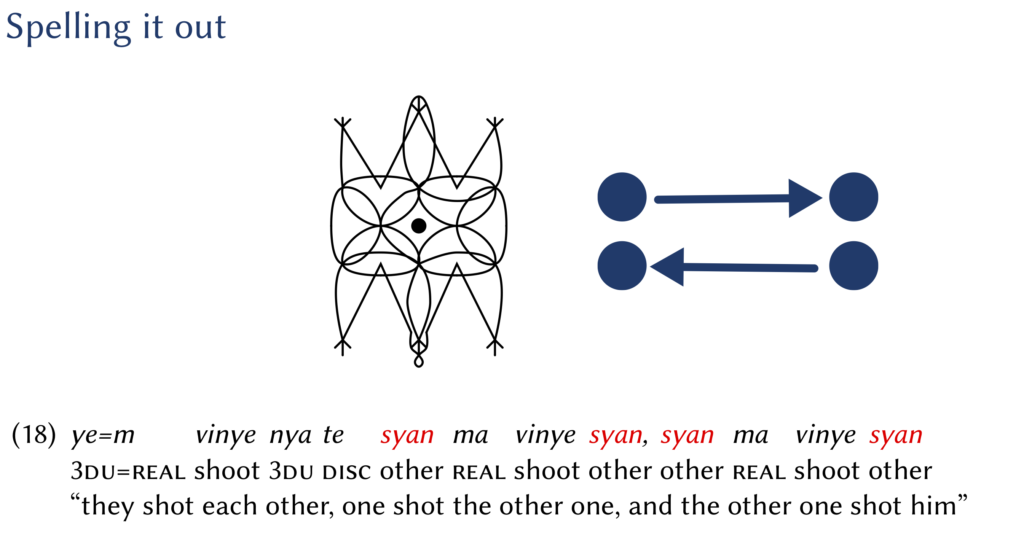
There was a very enlightening small workshop on reciprocals in Utrecht just now. I was invited to talk about reciprocals in Daakaka, which was an interesting assignment since Daakaka does not have reciprocal pronouns or verbal reciprocal morphology. Speakers do not have to distinguish between reciprocal, reflexive and regular transitive structures. There are however things they can do to facilitate, or force, reciprocal interpretations. Look at my slides to find out more.
Linguistics and ideologies in თბილისი

There was a wonderful small conference on Ideologies and Linguistic Ideas in beautiful Tbilisi last week, and I’m very happy I had the opportunity to team up with my colleague Marcin Kilarski to present some of our work on bias and ideologies in old and new debates on linguistic complexity. I also learned a lot about the role of ideologies in the history of linguistics, which is new and exciting territory to me. Download our slides here.
Realis and Irrealis at ALT, Pavia

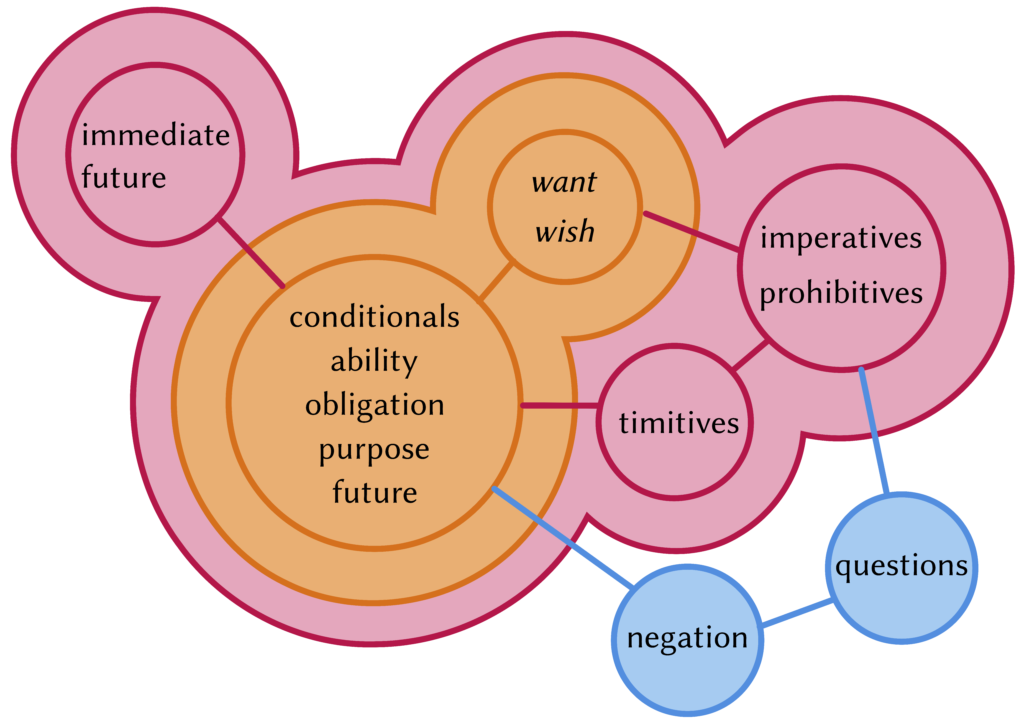
I heard many fantastic talks at this year’s ALT in Pavia and had some very inspiring conversations. The talk I gave was about realis and irrealis in Oceanic and beyond, and you can download the slides here.