
My proposal for a project on Oceanic Word Units was recently approved by the German Research Society! We’ll start in 2024, but I’m already excited and looking forward to diving into vowel harmony, clitics, and the morphosyntax of subject markers. You can read the proposal here.
Category: Events
Afaka font

I regularly go a little overboard when designing puzzles for the German Olympiad of Linguistics, but for one of this year’s puzzles, I really outnerded myself. I designed a True Type Font for the writing system Afaka, which was developed for the creole language Ndyuka. It was conceived in 1910 by Afáka Atumisi and is named after its inventor. It’s a syllabary, partially based on a rebus system.

For example, the symbol representing the syllable /fo/ shows four vertical lines. And there is an Afaka word pronounced “fo”, which means “four” (yes, it’s cognate with the English word).
There is a preliminary Unicode sheet with codes, but the writing system hasn’t been fully developed and codified so far. Accordingly, my font is also only a preliminary solution to writing Ndyuka in Afaka script. But it’s great for playing around, and designing puzzles! You can download the font here.
German Olympiad of Linguistics
I am heavily involved in organizing the German Olympiad of Linguistics each year (Deutsche Linguistik-Olympiade, DOL). I am primarily responsible for designing, curating and testing puzzles for the three rounds of competitions we host. In order to gain more support, we got together to found a “Verein”, the kind of institution that makes Germany go round. It’s been a rocky ride so far, but our students managed to collect some major prizes during this year’s IOL, so it’s all worth it! Take a look at the official DOL website here!
Freiburg 2022
The semester ended for me with a highly enjoyable visit at Uta Reinöhl’s lab in sunny Freiburg. I took the opportunity to talk about a puzzle concerning the role and emergence of word units in Oceanic. I’m currently writing a research proposal in the context of a Collaborative Research Centre we’re cooking up at HHU, where I hope to shed more light on this fascinating conundrum.
The German Olympiad of Linguistics (DOL)
Last weekend, we had the last round of the German Olympiad of Linguistics (it’s really the selection of the German teams to the International Olympiad of Linguistics, but that’s even more verbose). Designing that last set of puzzles in time hasn’t been easy, but I had awesome support from my colleagues Ruben Van de Vijver and Johanna Mattissen, who gave me very nice datasets for the construction of puzzles from Dutch and Nivkh. My student Alina Schünemann with her friend Augusta Ogechi Chukwu designed a wonderful puzzle on Igbo. And my student assistants tried and tested them. If you think you can best the high school students who cracked these puzzles in well below two hours (and if your German is sufficient), you can try your hand at them (solutions to follow soon).
AFLA 2020
I’m very excited about this year’s AFLA 2020. The organizers are doing a fantastic job at hosting it online. You can see the program and download all the slides here. There is also a youtube channel where all the talks have been posted. I haven’t been able to see all talks live so far, due to different time zones, but I have been very impressed with the quality of those talks that I have seen. It’s definitely worth taking a look. I used my slot to work on my greater narrative about how Oceanic languages can change our understanding about the relation between tense and modality, and between time and reality.
The German Olympic Linguists
I should have gotten around to this earlier, but here goes: Together with my colleagues at ZAS, Nathalie Topaj and André Meinunger, I organized the selection of the German team for the International Olympiad of Linguistics again this year, even though there it won’t take place this year.There is a short report on the ZAS homepage.
We have always been dealing with scarce resources, but this year, of course, also had to figure in the pandemic. We held all three rounds of competitions online. I missed talking to the students in present. Even so, I think we all had great fun with the puzzles. I had lots of help from colleagues in designing the puzzles, in particular Qiang Xia, Johanna Kimmerl, Christian Döhler and Sebastian Nordhoff, so we ended up with a fantastic range of languages and phenomena. I’m planning to make all puzzles accessible to the public eventually.
Paradigms and rules
I was invited to the University of Potsdam to talk about some of my recent work on morphology. I took the opportunity to discuss some of my observations about word-like properties of complex phrases, in particular the way they combine into word-like paradigms. You can see my slides here.
How many books fit into a suitcase?

Turns out, not that many. I’m moving offices from HU to ZAS right now, and it will take a few more trips through Berlin Mitte before the handsome shelves of my new office are filled. I’ll post more about my new position and rewrite my landing page as soon as I’ve figured out who I am right now, so watch this space.
Reciprocal strategies in a language without reciprocal markers
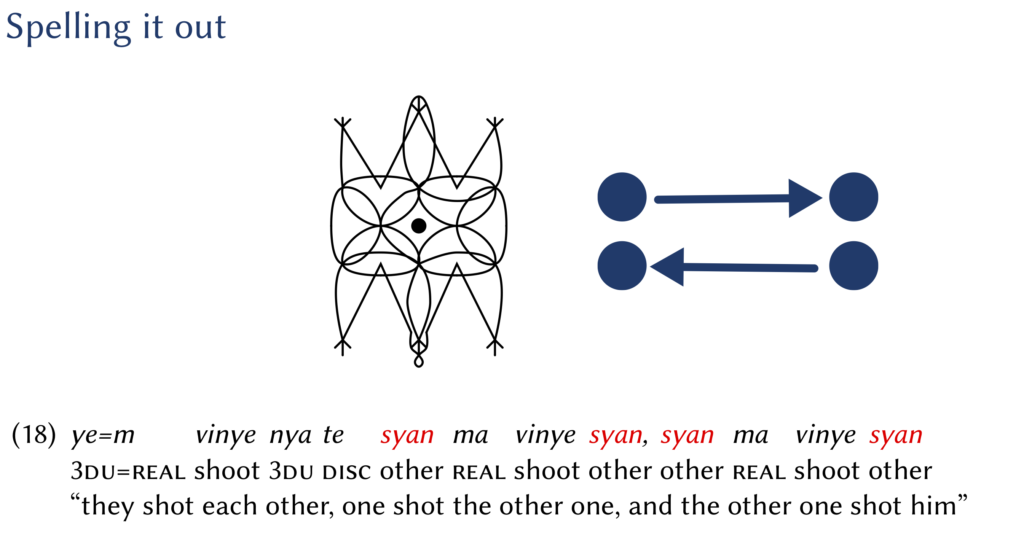
There was a very enlightening small workshop on reciprocals in Utrecht just now. I was invited to talk about reciprocals in Daakaka, which was an interesting assignment since Daakaka does not have reciprocal pronouns or verbal reciprocal morphology. Speakers do not have to distinguish between reciprocal, reflexive and regular transitive structures. There are however things they can do to facilitate, or force, reciprocal interpretations. Look at my slides to find out more.