
My proposal for a project on Oceanic Word Units was recently approved by the German Research Society! We’ll start in 2024, but I’m already excited and looking forward to diving into vowel harmony, clitics, and the morphosyntax of subject markers. You can read the proposal here.
News
Afaka font

I regularly go a little overboard when designing puzzles for the German Olympiad of Linguistics, but for one of this year’s puzzles, I really outnerded myself. I designed a True Type Font for the writing system Afaka, which was developed for the creole language Ndyuka. It was conceived in 1910 by Afáka Atumisi and is named after its inventor. It’s a syllabary, partially based on a rebus system.

For example, the symbol representing the syllable /fo/ shows four vertical lines. And there is an Afaka word pronounced “fo”, which means “four” (yes, it’s cognate with the English word).
There is a preliminary Unicode sheet with codes, but the writing system hasn’t been fully developed and codified so far. Accordingly, my font is also only a preliminary solution to writing Ndyuka in Afaka script. But it’s great for playing around, and designing puzzles! You can download the font here.
Custom typological maps with R
I used to plot my typological language data to geo-spatial maps with Generic Mapping Tools, which is awesome, and where a simple two-liner will do the job. But I found this hard to use in teaching, since it doesn’t run smoothly on everyone’s operating system. So it’s time for me to move on and learn to do maps with R. There are a few awesome resources out there, including lingtypology, which reads data directly off glottolog.
But I wanted to plot data that is not included in a database, and since it’s actually easy, but not entirely trivial to find on the internet so far, here’s a short tutorial. First of all, here is our little data set, with geo-spatial coordinates for each language, language family and basic word order info. Save this to a text file in your working directory with the name “typology.txt”.
Language,Latitude,Longitude,Family,Family2,Word order
Movima,-13.81,-65.63,Isolate,9,0
Arapaho,43.39,-108.81,Algic,10,OV
Alta,15.69,121.45,Austronesian,12,OV
Savosavo,-9.13,159.81,Isolate,9,OV
Teop,-5.67,154.97,Austronesian,11,VO
Sumi,26,94.42,Sino-Tibetan,12,VO
Yali,-4.08,139.46,Nuclear-Trans-New-Guinea,13,OV
Beja,17.24,36.67,Afro-Asiatic,14,VO
Vera'a,-13.89,167.43,Austronesian,11,OV
Cabecar,9.67,-83.41,Chibchan,15,VO
Urum,42.04,43.99,Turkic,16,OV
Dolgan,71.11,94.29,Turkic,16,OV
Gorwaa,-4.24,35.8,Afro-Asiatic,14,OV
Pnar,24.82,92.26,Austroasiatic,17,0
Goemai,8.74,9.72,Afro-Asiatic,14,VO
English,53,-1,Indo-European,7,VO
Nung,-29.71,19.08,Tuu,18,VO
Bora,-2,-72.26,Boran,19,VSO
Nafsan,-17.7,168.38,Austronesian,11,OV
Komnzo,-8.65,141.52,Yam,20,OV
Kamas,55.07,94.83,Uralic,21,VO
Kakabe,10.6,-11.44,Mande,22,OV
Daakaka,-16.27,168.01,Austronesian,11,VONext in your R script, load the following packages. You might have to install them first:
library(ggplot2)
library(maps)
library(sf) #for advanced mapping options
library(viridisLite) #for pretty, color-blind friendly color palettesRead in your map data and your language coordinates and save them to short variables like “map” and “df” (for data frame).
df <- read.csv("typology.txt")
head(df) #shows you the beginning of the data, good for trouble shooting
map <- map_data("world")In order to plot your language coordinates with additional information about language families, do this:
#family
ggplot() +
geom_polygon(data = map, aes(x = long, y = lat, group=group), fill="#dddddd") + #plots the world map in the background in light grey
geom_point(data = df, aes(x = Longitude, y = Latitude, fill = factor(Family)), shape=21, size=3) + #plots the language coordinates
theme_minimal()+ #fewer embellishments
coord_sf()+ #nice proportions
scale_fill_viridis_d(option = "plasma")+ #color scheme
labs(fill = "Family", y="",x="") #labels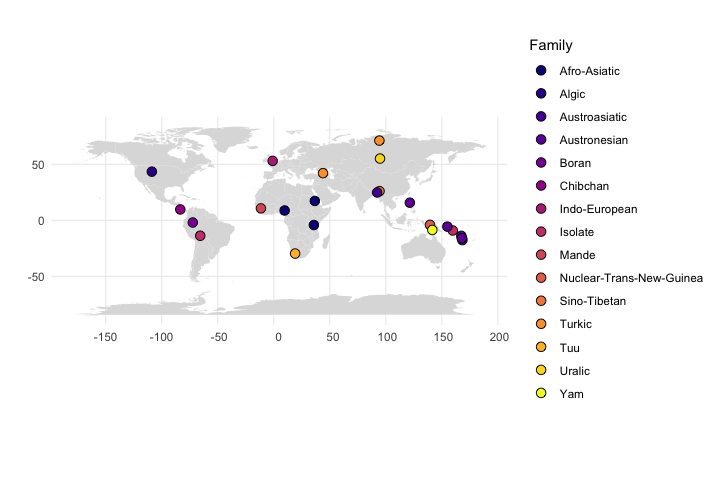
To get information about word order patterns, instead use this:
#word order
ggplot() +
geom_polygon(data = map, aes(x = long, y = lat, group = group), fill="#dddddd") +
geom_point(data = df, aes(x = Longitude, y = Latitude, fill = factor(Word.order)), shape=21, size=3) +
theme_minimal()+
coord_sf()+
scale_fill_viridis_d(option = "plasma")+
labs(fill = "Word Order", y="",x="")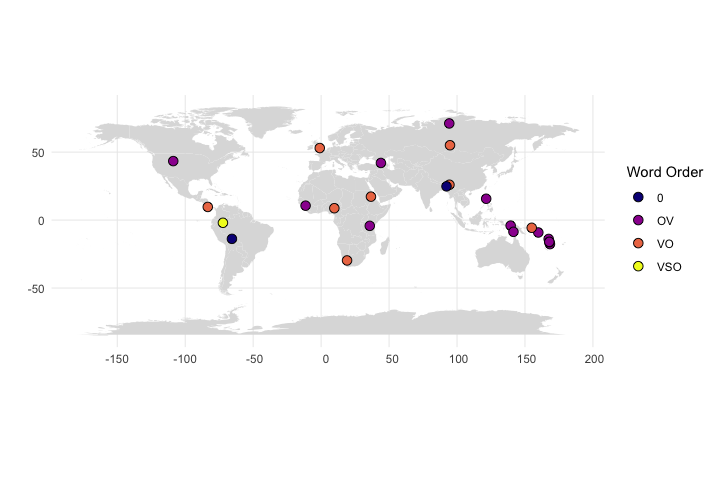
And since newbies sometimes use my tutorials: If you don’t understand something here, don’t give up, google it! Everyone does it, and most questions you might have, have already been asked and answered by someone somewhere.
Wrapping up 2022: more talks and publications
I haven’t been posting regularly about recent talks and publications, so here are a few more highlights from the second part of 2022:
- Colleagues and I published a paper on training RRG parsers on low resource languages, including Daakaka data.
- I gave a talk at the awesome linguistics department in Cologne, with a few more thoughts about wordhood in Daakaka.
- I was also invited to the phenomenal UT Texas (which curiously expands to University of Texas at Austin) department of linguistics, which combines two of my favourite subjects, linguistic fieldwork and formal semantics. This gave me a chance to get back to some of my ideas about modal semantics.
German Olympiad of Linguistics
I am heavily involved in organizing the German Olympiad of Linguistics each year (Deutsche Linguistik-Olympiade, DOL). I am primarily responsible for designing, curating and testing puzzles for the three rounds of competitions we host. In order to gain more support, we got together to found a “Verein”, the kind of institution that makes Germany go round. It’s been a rocky ride so far, but our students managed to collect some major prizes during this year’s IOL, so it’s all worth it! Take a look at the official DOL website here!
A Grammar of Daakaka online
My grammar of Daakaka, which was first published in print in 2015, is now available online from De Gruyter’s website. Please check if you can access it via your institution, or get in touch with me for a digital copy.
Freiburg 2022
The semester ended for me with a highly enjoyable visit at Uta Reinöhl’s lab in sunny Freiburg. I took the opportunity to talk about a puzzle concerning the role and emergence of word units in Oceanic. I’m currently writing a research proposal in the context of a Collaborative Research Centre we’re cooking up at HHU, where I hope to shed more light on this fascinating conundrum.
Irrealis is real
My paper with Ana Krajinović and Manfred Krifka on the role of irrealis in TAM systems is now online and free of charge. We use the tripartite model of branching time I developed in this other paper to account for the meanings of realis and irrealis markers in a variety of languages and delineate their role in human language, with a focus on Oceanic.
The German Olympiad of Linguistics (DOL)
Last weekend, we had the last round of the German Olympiad of Linguistics (it’s really the selection of the German teams to the International Olympiad of Linguistics, but that’s even more verbose). Designing that last set of puzzles in time hasn’t been easy, but I had awesome support from my colleagues Ruben Van de Vijver and Johanna Mattissen, who gave me very nice datasets for the construction of puzzles from Dutch and Nivkh. My student Alina Schünemann with her friend Augusta Ogechi Chukwu designed a wonderful puzzle on Igbo. And my student assistants tried and tested them. If you think you can best the high school students who cracked these puzzles in well below two hours (and if your German is sufficient), you can try your hand at them (solutions to follow soon).
More resources on Chinese
For my class on the structure of Chinese, I wanted to give my students some accessible resources so they can make their own observations. To that end, I translated and glossed some texts. Among them are the lyrics to one song, as described here earlier. In addition, I processed two literary texts this way (with translations to German, glosses in English). One is the beginning of Lu Xun’s “Diary of a Madman”, a paranoid, Kafkaesque and brilliant text. For this one, I took the time to add two levels of glosses, one with literal morpheme-by-morpheme translations, one with the lexicalized meanings of multi-character words. The other one is the beginning of “Brothers” by Yu Hua.
Continue reading “More resources on Chinese”