
I’m currently in Cologne at the small Vielfaltslinguistik Conference (Diversity linguistics). It’s great to see so much new and interesting work on lesser described languages. My own talk, on joined work with Manfred Krifka and Ana Krajinović, focuses on empirical methods in our MelaTAMP project. Our slides can be downloaded here: [download id=”473″].
Category: Publications
Habituality in four Oceanic languages
Our article (with Ana Krajinović, Anna Margetts, Nick Thieberger and Valérie Guérin) is out now and currently available for free here. In this article, we talk about habitual aspect in four Oceanic languages and demonstrate how it is (or isn’t) typically expressed. Reduplication and imperfective aspect play a particularly prominent role, sometimes in combination with each other.
Out now: Proceedings of Sinn und Bedeutung 21
The proceedings for Sinn und Bedeutung 21 is out now and available from here. Check out my article on how to derive the discontinuity implicature of past markers in Daakaka and elsewhere!
Counterfactuality and Past in Konstanz
 For my second talk in Konstanz, I discussed my paper on Counterfactuality and Past in the What-if group. You can download the current manuscript version here: [download id=”362″]. My slides can be found here: [download id=”367″].
For my second talk in Konstanz, I discussed my paper on Counterfactuality and Past in the What-if group. You can download the current manuscript version here: [download id=”362″]. My slides can be found here: [download id=”367″].
Mapping irreality in Konstanz
 Last week, I had the privilege of giving two talks in Konstanz. In the colloquium of the linguistics department, I talked about our latest research on counterfactual futures in Oceanic and what they tell us about tense and mood in our subject languages. Download the slides here: [download id=”348″]. Read the paper here: [download id=”358″].
Last week, I had the privilege of giving two talks in Konstanz. In the colloquium of the linguistics department, I talked about our latest research on counterfactual futures in Oceanic and what they tell us about tense and mood in our subject languages. Download the slides here: [download id=”348″]. Read the paper here: [download id=”358″].
Mapping Irreality in Göttingen
 I went to Göttingen last week to talk about modality, which is turning into a pleasant tradition. In my talk, I outlined the typological debate on the irrealis distinction, introduced the tripartite branching-time model that I think will help us the relevant cross-linguistic variation, and discussed how the same approach also sheds new light on some long-standing questions about the nature of modality, counterfactuality and epistemic necessity. You can find the slides here.
I went to Göttingen last week to talk about modality, which is turning into a pleasant tradition. In my talk, I outlined the typological debate on the irrealis distinction, introduced the tripartite branching-time model that I think will help us the relevant cross-linguistic variation, and discussed how the same approach also sheds new light on some long-standing questions about the nature of modality, counterfactuality and epistemic necessity. You can find the slides here.
Complexity at the POS level
There was an interesting small workshop in Torun in April on Measuring Linguistic Complexity. When the call came out, I had just finished a preliminary overview on the previous literature on the topic and was ready to get cracking, so I got together with Vera Demberg to test our hypothesis that focussing on POS tags rather than the token-level annotations would give us more reliable results on syntactic flexibility. Our results are in the proceedings.
Grammaticalisation and information density
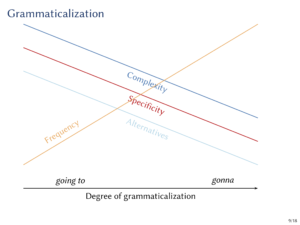 My work in the Collaborative Research Unit on information density (ID) in Saarbrücken has made me think about the relation between grammaticalisation and ID. In an invited talk to Saarbrücken in April, I explored some of my ideas on this topic. You can find the slides here.
My work in the Collaborative Research Unit on information density (ID) in Saarbrücken has made me think about the relation between grammaticalisation and ID. In an invited talk to Saarbrücken in April, I explored some of my ideas on this topic. You can find the slides here.
Poster at Linguistic Evidence in Tübingen
 The Linguistic Evidence conference in Tübingen this year is long over and I’m sad I couldn’t be there, but our poster was well represented by my two co-authors, Manfred Krifka and Ana Krajinović. Click here to download the PDF.
The Linguistic Evidence conference in Tübingen this year is long over and I’m sad I couldn’t be there, but our poster was well represented by my two co-authors, Manfred Krifka and Ana Krajinović. Click here to download the PDF.
Last talk of 2017, at the MPI for the Science of Human History
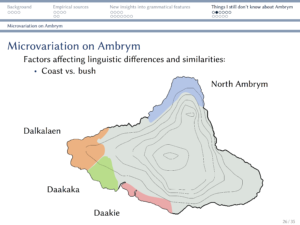 2017 was a year full of talks, so don’t be surprised if you won’t see me on the circuit as much during 2018. The last talk of that year was at the MPI in Jena, where I talked about some of the things you’ll see if you compare languages based on corpus data that you’re likely to miss if you look at grammatical descriptions. I had some incredibly inspiring conversations and hope to visit more often (maybe even in 2018).
2017 was a year full of talks, so don’t be surprised if you won’t see me on the circuit as much during 2018. The last talk of that year was at the MPI in Jena, where I talked about some of the things you’ll see if you compare languages based on corpus data that you’re likely to miss if you look at grammatical descriptions. I had some incredibly inspiring conversations and hope to visit more often (maybe even in 2018).