

There was a wonderful small conference on Ideologies and Linguistic Ideas in beautiful Tbilisi last week, and I’m very happy I had the opportunity to team up with my colleague Marcin Kilarski to present some of our work on bias and ideologies in old and new debates on linguistic complexity. I also learned a lot about the role of ideologies in the history of linguistics, which is new and exciting territory to me. Download our slides here.
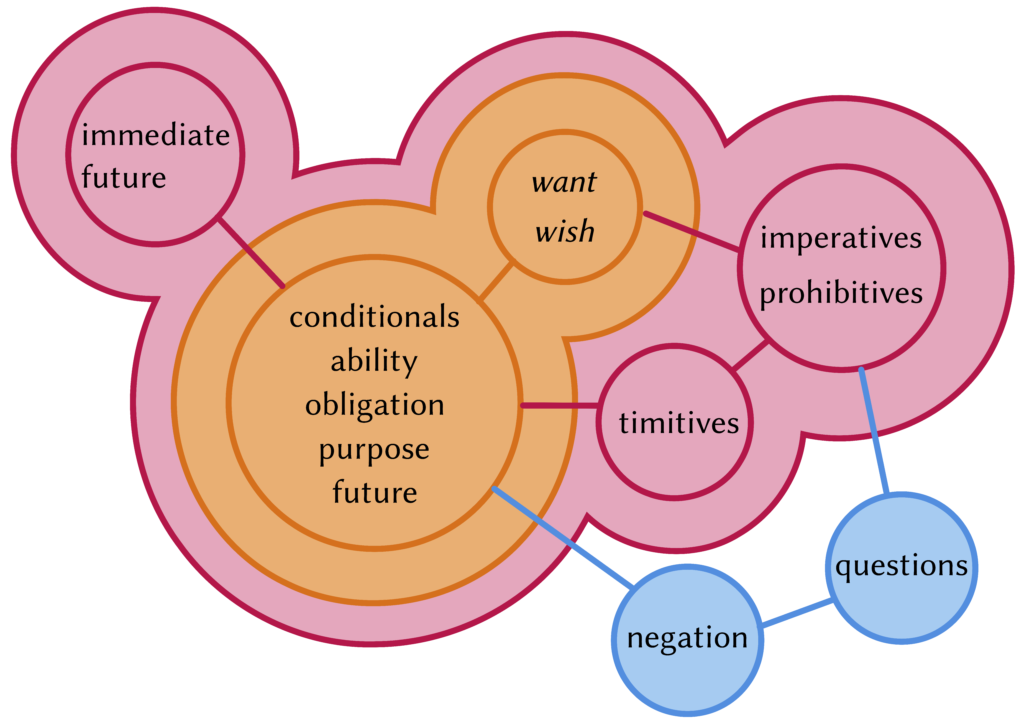

 My colleagues Ana Krajinović and Manfred Krifka are currently at APLL in Leiden to present our joint work on timitive structures in Oceanic, which have the shape it’s not good/it’s bad if… . Timitive modality is a category often found in Oceanic, which typically occurs in warnings (Watch out, you might fall!) or negative purpose clauses (You should take an umbrella, lest you get wet!). Download the poster
My colleagues Ana Krajinović and Manfred Krifka are currently at APLL in Leiden to present our joint work on timitive structures in Oceanic, which have the shape it’s not good/it’s bad if… . Timitive modality is a category often found in Oceanic, which typically occurs in warnings (Watch out, you might fall!) or negative purpose clauses (You should take an umbrella, lest you get wet!). Download the poster  For my second talk in Konstanz, I discussed my paper on Counterfactuality and Past in the
For my second talk in Konstanz, I discussed my paper on Counterfactuality and Past in the