
Opening the mail…
Once you have submitted your article to a research journal, it can take a few weeks to a few months before you hear back. During that time, your editors are busy finding competent and willing reviewers, and hopefully, those reviewers are busy reading your work with discretion and charity and thinking about the best ways to help you improve your manuscript. If you do not hear back from the editors after 3 months, feel free to send them a friendly reminder that you are still waiting for reviews.
Continue reading “How to revise your article after reviewing”
 For my second talk in Konstanz, I discussed my paper on Counterfactuality and Past in the
For my second talk in Konstanz, I discussed my paper on Counterfactuality and Past in the  Last week, I had the privilege of giving two talks in Konstanz. In the colloquium of the linguistics department, I talked about our latest research on counterfactual futures in Oceanic and what they tell us about tense and mood in our subject languages. Download the slides here: [download id=”348″]. Read the paper here: [download id=”358″].
Last week, I had the privilege of giving two talks in Konstanz. In the colloquium of the linguistics department, I talked about our latest research on counterfactual futures in Oceanic and what they tell us about tense and mood in our subject languages. Download the slides here: [download id=”348″]. Read the paper here: [download id=”358″]. I went to Göttingen last week to talk about modality, which is turning into a pleasant tradition. In my talk, I outlined the typological debate on the irrealis distinction, introduced the tripartite branching-time model that I think will help us the relevant cross-linguistic variation, and discussed how the same approach also sheds new light on some long-standing questions about the nature of modality, counterfactuality and epistemic necessity. You can find the slides
I went to Göttingen last week to talk about modality, which is turning into a pleasant tradition. In my talk, I outlined the typological debate on the irrealis distinction, introduced the tripartite branching-time model that I think will help us the relevant cross-linguistic variation, and discussed how the same approach also sheds new light on some long-standing questions about the nature of modality, counterfactuality and epistemic necessity. You can find the slides 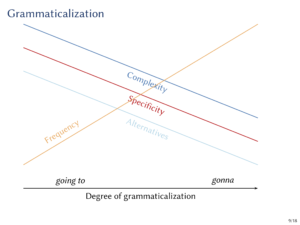 My work in the Collaborative Research Unit on information density (ID) in Saarbrücken has made me think about the relation between grammaticalisation and ID. In an invited talk to Saarbrücken in April, I explored some of my ideas on this topic. You can find the slides
My work in the Collaborative Research Unit on information density (ID) in Saarbrücken has made me think about the relation between grammaticalisation and ID. In an invited talk to Saarbrücken in April, I explored some of my ideas on this topic. You can find the slides