
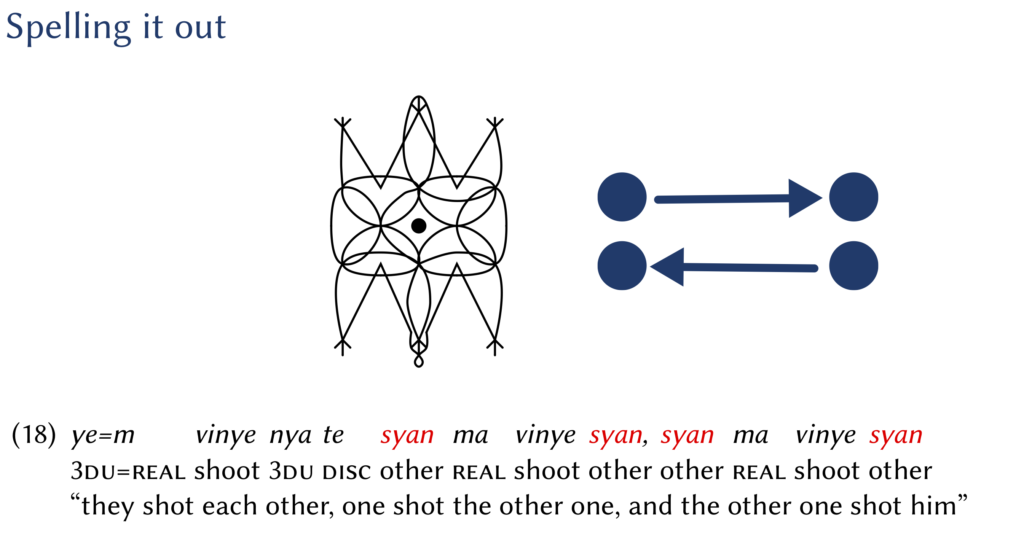
There was a very enlightening small workshop on reciprocals in Utrecht just now. I was invited to talk about reciprocals in Daakaka, which was an interesting assignment since Daakaka does not have reciprocal pronouns or verbal reciprocal morphology. Speakers do not have to distinguish between reciprocal, reflexive and regular transitive structures. There are however things they can do to facilitate, or force, reciprocal interpretations. Look at my slides to find out more.

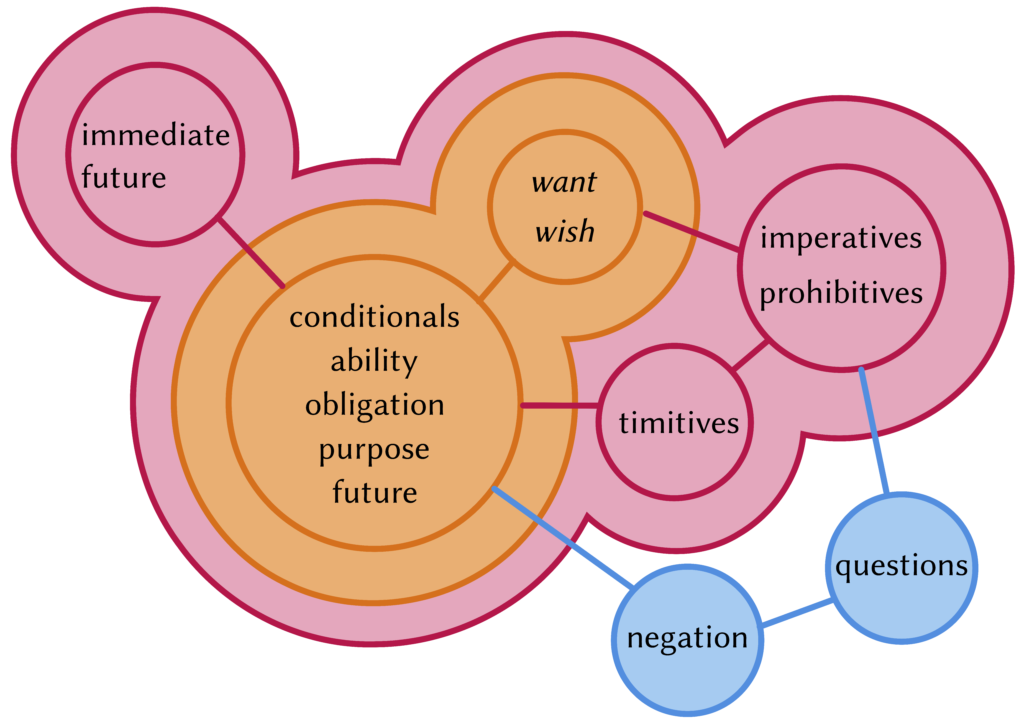
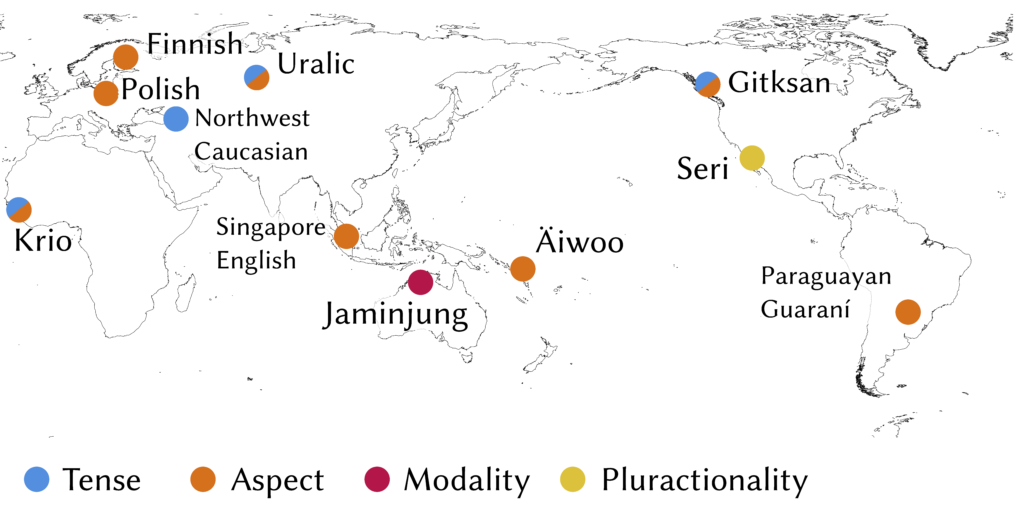

 My colleagues Ana Krajinović and Manfred Krifka are currently at APLL in Leiden to present our joint work on timitive structures in Oceanic, which have the shape it’s not good/it’s bad if… . Timitive modality is a category often found in Oceanic, which typically occurs in warnings (Watch out, you might fall!) or negative purpose clauses (You should take an umbrella, lest you get wet!). Download the poster
My colleagues Ana Krajinović and Manfred Krifka are currently at APLL in Leiden to present our joint work on timitive structures in Oceanic, which have the shape it’s not good/it’s bad if… . Timitive modality is a category often found in Oceanic, which typically occurs in warnings (Watch out, you might fall!) or negative purpose clauses (You should take an umbrella, lest you get wet!). Download the poster